Overview
This tutorial walks you through the complete workflow of performing vector search in MongoDB Atlas — from generating text embeddings to constructing aggregation pipelines with and without pre-filters.
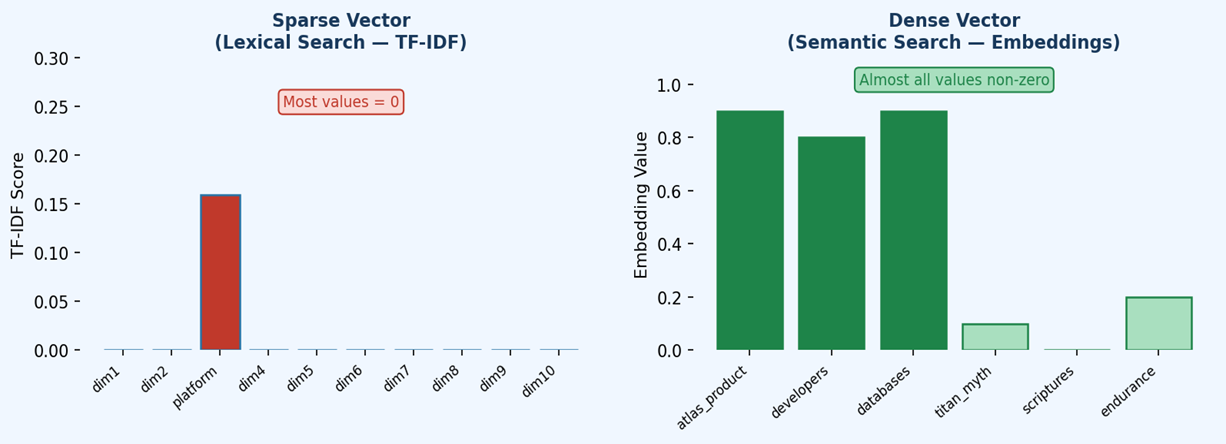
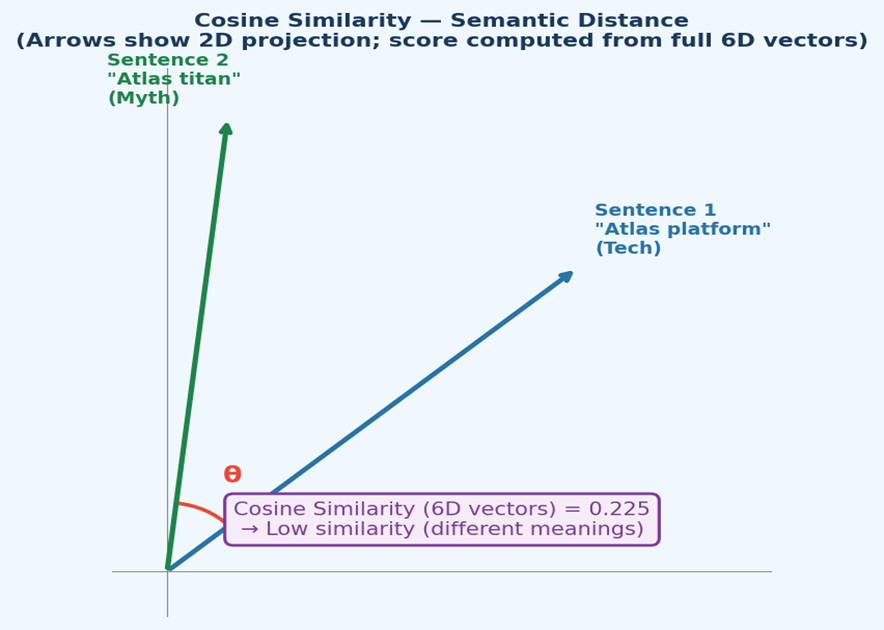
Vector search enables semantic similarity queries: instead of matching exact keywords, you find documents whose meaning is closest to your query. This is the engine behind modern AI features like RAG (Retrieval-Augmented Generation), recommendation systems, and intelligent document search.
Prerequisites
- A running MongoDB Atlas cluster (A MongoDB Atlas cluster M0 tier (free) should be sufficient)
- A collection with documents that have an embedding field (e.g.,
plot_embedding) - A Vector Search index already created on the collection (see the Index Setup section below)
- An API key for Voyage AI (or another embedding provider)
- Python environment with
pymongoandvoyageaipackages installed
Table of Contents
- What is a Vector Embedding?
- Step 1 — Embedding Model: Voyage AI voyage-3.5-lite
- Step 2 — Generate and Store Document Embeddings
- Step 3 — Create a Vector Search Index
- Step 4 — Generate a Query Embedding
- Step 5 — Build the Vector Search Pipeline
- Step 6 — Vector Search with a Pre-Filter
- Deep Dive: How HNSW Powers Vector Search
- Tuning numCandidates for Optimal Performance
- ANN vs. Exact Search
- Understanding vectorSearchScore
- Common Pitfalls
- Quick Reference
What is a Vector Embedding?
A vector embedding is a dense numerical representation of text (or other data) in a high-dimensional space. Semantically similar texts are placed closer together in this space.
"A dog running in the park" → [0.12, -0.45, 0.87, ..., 0.03] (1024 numbers)
"A puppy playing outdoors" → [0.13, -0.43, 0.89, ..., 0.02] ← very similar!
"The stock market crashed" → [-0.91, 0.22, -0.54, ..., 0.77] ← very different
Similarity is measured using distance metrics:
| Metric | Formula | Best For |
|---|---|---|
| Cosine | $1 - (A·B / |A||B|)$ | Text similarity (most common) |
| Dot Product | $A·B$ | Normalized vectors, fast ranking |
| Euclidean | $\sqrt{\sum(A_i - B_i)^2}$ | When magnitude matters |
Step 1 — Embedding Model: Voyage AI voyage-3.5-lite
The examples in this tutorial use the voyage-3.5-lite embedding model from Voyage AI — a state-of-the-art, cost-efficient model optimized for large-scale retrieval and RAG applications.
Key Specifications
| Property | Value |
|---|---|
| Supported Dimensions | 2048, 1024 (default), 512, 256 |
| Context Length | 32,000 tokens |
| Quantization Types | float (default), int8, uint8, binary, ubinary |
| Use Cases | Technical docs, code, law, finance, web reviews, conversations |
Why Flexible Dimensions?
voyage-3.5-lite uses Matryoshka Representation Learning (MRL) — a technique where the first N dimensions of a larger embedding already form a high-quality, lower-dimensional embedding. This means you can truncate the vector to save storage without dramatically hurting recall quality.
2048-dim → high quality, high storage cost
1024-dim → balanced (default)
512-dim → compact, good for memory-constrained deployments
256-dim → smallest, fastest, some quality trade-off
Quantization Tradeoffs
Quantization reduces the precision of each floating-point number:
| Type | Storage Reduction | Recall Impact |
|---|---|---|
float |
Baseline | None (highest quality) |
int8 |
~75% reduction | Minimal |
binary |
~97% reduction | Moderate — use with binary rescoring |
Tip: Using
int8at 2048 dimensions can reduce vector DB costs by ~83% vs. standard float embeddings, per Voyage AI documentation.
Step 2 — Generate and Store Document Embeddings
Before you can run vector search queries, each document in your collection must have an embedding field that stores the vector.
Installation
pip install voyageai pymongo
Generating Embeddings for Documents
import voyageai
from pymongo import MongoClient
# --- Setup ---
vo = voyageai.Client(api_key="YOUR_VOYAGE_API_KEY")
client = MongoClient("YOUR_MONGODB_CONNECTION_STRING")
db = client["sample_mflix"]
collection = db["movies"]
def generate_embedding(text: str) -> list[float]:
"""
Generate an embedding vector for a given text using voyage-3.5-lite.
The input_type="document" instructs the model to optimize the embedding
for storage/retrieval (as opposed to "query" for query-time embeddings).
"""
result = vo.embed(
texts=[text],
model="voyage-3.5-lite",
input_type="document"
)
return result.embeddings[0]
# --- Embed and store each document ---
# This iterates over documents that have a 'plot' field but no embedding yet.
for doc in collection.find({"plot": {"$exists": True}, "plot_embedding": {"$exists": False}}):
embedding = generate_embedding(doc["plot"])
collection.update_one(
{"_id": doc["_id"]},
{"$set": {"plot_embedding": embedding}}
)
print(f"Embedded: {doc.get('title', 'Unknown')}")
print("Done embedding all documents.")
Why input_type="document" vs "query"?
Voyage AI distinguishes between embedding documents (stored content) and queries (search input). Using the correct type ensures the model applies appropriate asymmetric transformations for optimal retrieval performance.
Step 3 — Create a Vector Search Index
A Vector Search Index tells MongoDB Atlas which field holds the embedding vectors, how many dimensions those vectors have, and which similarity metric to use.
Basic Vector Search Index
// MongoDB Shell
db.movies.createSearchIndex(
"vectorPlotIndex", // index name
"vectorSearch", // index type
{
"fields": [
{
"type": "vector",
"path": "plot_embedding", // field storing the embedding
"numDimensions": 1024, // must match your embedding model's output dimension
"similarity": "cosine" // cosine | dotProduct | euclidean
}
]
}
);
Critical:
numDimensionsmust exactly match the dimension your embedding model outputs. Forvoyage-3.5-litewith default settings, this is 1024. Mismatched dimensions cause index failures or zero results.
Vector Search Index with Pre-filter Support
If you want to filter your vector search results by scalar fields (e.g., year, genre, rating), you must declare those fields as "type": "filter" in the index definition:
db.movies.createSearchIndex(
"vectorPlotIndex",
"vectorSearch",
{
"fields": [
{
"type": "vector",
"path": "plot_embedding",
"numDimensions": 1024,
"similarity": "cosine"
},
{
"type": "filter",
"path": "year" // enables pre-filtering on the year field
}
]
}
);
Step 4 — Generate a Query Embedding
At query time, you must convert your search text into a vector using the same model that was used to embed the documents.
def generate_query_embedding(query_text: str) -> list[float]:
"""
Generate an embedding for a search query using voyage-3.5-lite.
input_type="query" optimizes the embedding for retrieval (asymmetric search).
This is DIFFERENT from document embeddings — use the correct type!
"""
result = vo.embed(
texts=[query_text],
model="voyage-3.5-lite",
input_type="query"
)
return result.embeddings[0]
# Example: generate embedding for a user's search query
query_text = "movies about space exploration and astronauts"
query_embedding = generate_query_embedding(query_text)
Important: Always use
input_type="query"for query-time embeddings. Using"document"for queries reduces retrieval quality.
Step 5 — Build the Vector Search Pipeline
MongoDB Atlas Vector Search uses the $vectorSearch aggregation stage. It must be the first stage in an aggregation pipeline.
The $vectorSearch Stage Syntax
pipeline = [
{
"$vectorSearch": {
"index": "vectorPlotIndex", # name of the vector search index
"path": "plot_embedding", # field containing the embeddings
"queryVector": query_embedding, # the query vector (list of floats)
"numCandidates": 100, # pool size for ANN search (omit for exact)
"limit": 10, # number of final results to return
"exact": False # False = ANN search (default), True = exact
}
},
{
"$project": {
"title": 1,
"plot": 1,
"score": {"$meta": "vectorSearchScore"} # retrieves the similarity score
}
}
]
results = collection.aggregate(pipeline)
for movie in results:
print(f"{movie['title']} — Score: {movie['score']:.4f}")
print(f" {movie['plot']}\n")
Field Reference
| Field | Required | Description |
|---|---|---|
index |
✅ | Name of the vector search index to use |
path |
✅ | Dot-notation path to the embedding field in documents |
queryVector |
✅ | The query vector as a list of floats |
numCandidates |
✅ (ANN) | Number of nearest neighbor candidates to explore; omit when exact: true |
limit |
✅ | Maximum number of documents returned |
exact |
❌ | false (default) uses ANN/HNSW; true uses brute-force exact search |
filter |
❌ | MongoDB query expression for pre-filtering (requires filter field in index) |
Step 6 — Vector Search with a Pre-Filter
Pre-filtering narrows the search space before vector similarity is computed. This is more efficient than post-filtering with a $match stage because it avoids examining irrelevant vectors entirely.
Why Pre-Filtering Requires Index Configuration
When you use a filter in $vectorSearch, Atlas must be able to evaluate that filter condition using the vector index metadata. This is why the filter field (e.g., year) must be declared with "type": "filter" in the index definition.
pipeline = [
{
"$vectorSearch": {
"index": "vectorPlotIndex",
"path": "plot_embedding",
"queryVector": query_embedding,
"numCandidates": 100,
"filter": {"year": {"$gt": 2010}}, # pre-filter: only movies after 2010
"limit": 10
}
},
{
"$project": {
"title": 1,
"plot": 1,
"year": 1,
"score": {"$meta": "vectorSearchScore"}
}
}
]
results = collection.aggregate(pipeline)
for movie in results:
print(f"[{movie['year']}] {movie['title']} — Score: {movie['score']:.4f}")
Supported Filter Operators
The filter field accepts standard MongoDB query operators on indexed filter fields:
| Operator | Example | Description |
|---|---|---|
$eq |
{"genre": {"$eq": "Action"}} |
Exact match |
$ne |
{"genre": {"$ne": "Horror"}} |
Not equal |
$gt / $gte |
{"year": {"$gt": 2010}} |
Greater than |
$lt / $lte |
{"rating": {"$lt": 8.0}} |
Less than |
$in |
{"genre": {"$in": ["Action", "Sci-Fi"]}} |
Match any in list |
$and |
{"$and": [...]} |
Combine multiple conditions |
Source: MongoDB $vectorSearch Reference
Deep Dive: How HNSW Powers Vector Search
When you run a vector search query, MongoDB Atlas uses the Hierarchical Navigable Small World (HNSW) algorithm to efficiently find approximate nearest neighbors.
The HNSW Graph Structure
HNSW builds a multi-layered graph during index construction:
Layer 2 (sparse, fast navigation):
[A] ──────────────── [B]
Layer 1 (intermediate):
[A] ── [C] ── [B] ── [D]
Layer 0 (all nodes, most edges):
[A] ── [C] ── [E] ── [B] ── [D] ── [F] ── [G]
- Layer 0 contains ALL data points with many connections
- Upper layers contain progressively fewer points (selected probabilistically)
- Each node connects to its k-nearest neighbors at each layer
The ANN Search Algorithm (Greedy Traversal)
When you submit a query, HNSW searches as follows:
- Enter at top layer — start from a fixed entry point at the highest layer
- Greedy descent — at each layer, navigate to the neighbor closest to the query vector
- Descend when stuck — when no neighbor at the current layer is closer than the current node, descend to the layer below
- Exhaustive search at Layer 0 — controlled by the
efparameter, which determines how many candidate nodes to explore at the base layer - Return top-k results — the closest
limitcandidates from Layer 0 are returned
Query: Q = "movies about space exploration"
Layer 2: Enter at node A → navigate toward B (closer to Q)
Layer 1: From B, find D (closer to Q)
Layer 0: From D, exhaustively check neighbors within ef budget → return top 10
HNSW Configuration Parameters
| Parameter | Default | Range | Effect |
|---|---|---|---|
m (maxEdges) |
16 | 4–96 | Connections per node. Higher = better recall, more memory |
efConstruction |
100 | 10–3200 | Candidates during index build. Higher = better index quality, slower build |
ef |
40 | — | Candidates at query time. Higher = better recall, slower queries |
Source: MongoDB HNSW Documentation
Tuning numCandidates for Optimal Performance
numCandidates controls the pool of candidate vectors that HNSW explores at query time. It directly affects the recall vs. speed tradeoff.
Recommended Starting Point
MongoDB recommends setting
numCandidatesto at least 10x–20x the value oflimit.
# Example: limit=10, numCandidates=100 → 10x ratio (good baseline)
# For higher recall: numCandidates=200 → 20x ratio
Tuning Guidelines
| Factor | Guidance |
|---|---|
| Index Size | Larger collections → increase numCandidates. More vectors means you need a bigger candidate pool to find the true nearest neighbors. |
| Limit Value | Lower limit → proportionally higher numCandidates ratio needed. If limit=5, use numCandidates >= 100. |
| Quantized Vectors | int8/binary quantization introduces approximation error → increase numCandidates to compensate and maintain recall. |
| Filter + numCandidates | When using pre-filters, numCandidates refers to candidates within the filtered set. If the filtered set is small, keep numCandidates reasonable. |
Recall vs. Speed Tradeoff Visualization
numCandidates = 20 → Fast, lower recall (may miss good results)
numCandidates = 100 → Balanced (recommended starting point)
numCandidates = 500 → Slower, higher recall
numCandidates = 1000 → Approaches exact search quality but much slower
ANN vs. Exact Search
Approximate Nearest Neighbor (ANN) Search — Default
Used when "exact": False (or exact is omitted).
{
"$vectorSearch": {
"index": "vectorPlotIndex",
"path": "plot_embedding",
"queryVector": query_embedding,
"numCandidates": 100, # REQUIRED for ANN
"limit": 10,
"exact": False # default — uses HNSW
}
}
Characteristics:
- ⚡ Fast — O(log n) with HNSW graph traversal
- 📊 High recall in practice — typically 95-99% of true nearest neighbors
- 📈 Scalable — works well with millions of vectors
- ❌ Not guaranteed exact — may occasionally miss a true nearest neighbor
Exact (Brute-Force) Search
Used when "exact": True. Do NOT specify numCandidates — it is ignored (and causes an error in some versions).
{
"$vectorSearch": {
"index": "vectorPlotIndex",
"path": "plot_embedding",
"queryVector": query_embedding,
# numCandidates must be OMITTED for exact search
"limit": 10,
"exact": True # brute-force: checks every vector
}
}
Characteristics:
- ✅ Guaranteed correct — always returns the true nearest neighbors
- 🐢 Slow — O(n) — computes distance to every vector in the collection
- ⚠️ Not production-ready for large datasets — use for small datasets or validation only
- 🔬 Best use case — benchmarking and validating ANN results
When to Use Each
| Use Case | Recommendation |
|---|---|
| Production queries on large collections | ANN (exact: False) |
| Development/debugging | Either; ANN is usually fine |
| Validating ANN recall quality | Exact (exact: True) on a sample |
| Collections < 1,000 vectors | Either; difference is negligible |
| RAG pipelines | ANN with well-tuned numCandidates |
Understanding vectorSearchScore
The $meta: "vectorSearchScore" expression retrieves the similarity score for each result. Understanding what this score means helps you set meaningful confidence thresholds.
{
"$project": {
"title": 1,
"score": {"$meta": "vectorSearchScore"}
}
}
Score Interpretation by Similarity Metric
| Similarity | Score Range | Higher = ? |
|---|---|---|
| cosine | 0.0 – 1.0 | More similar (1.0 = identical direction) |
| dotProduct | Unbounded | More similar |
| euclidean | 0.0 – 1.0 (normalized) | More similar (inverted distance) |
Using Scores as Confidence Thresholds
You can post-filter results by score using a $match stage after $vectorSearch:
pipeline = [
{
"$vectorSearch": {
"index": "vectorPlotIndex",
"path": "plot_embedding",
"queryVector": query_embedding,
"numCandidates": 100,
"limit": 50 # fetch more candidates
}
},
{
# Post-filter: only keep results with similarity > 0.75
"$match": {
"score": {"$gt": 0.75}
}
},
{
"$project": {
"title": 1,
"score": {"$meta": "vectorSearchScore"},
"plot": 1
}
},
{"$limit": 10} # then limit final output
]
⚠️ Note:
$matchonscoreis a post-filter and runs after the vector search. It does not reduce the number of vectors examined — it only filters the returned results. This is different from thefilterparameter in$vectorSearch.
Common Pitfalls
1. Mismatched Embedding Dimensions
Error: Vector dimension mismatch
Cause: numDimensions in the index ≠ actual length of the embedding vector.
Fix: Ensure the dimension in the index definition exactly matches your embedding model’s output dimension (e.g., 1024 for voyage-3.5-lite default).
2. Using numCandidates with exact: True
Error: numCandidates cannot be specified with exact search
Fix: Remove numCandidates when setting "exact": True.
3. Filter Field Not in Index
Error: Filter field 'year' is not indexed
Cause: Trying to use filter: {"year": ...} when year was not added as a "type": "filter" field in the vector search index.
Fix: Recreate the index including {"type": "filter", "path": "year"}.
4. Different Models for Documents and Queries
Cause: Embedding documents with voyage-3.5-lite but querying with text-embedding-ada-002 (or any other model).
Effect: Vectors live in completely different semantic spaces — results will be meaningless.
Fix: Always use the same model and the same dimension for both document embeddings and query embeddings.
5. Low numCandidates → Poor Recall
Symptom: Vector search returns results that don’t seem semantically relevant.
Fix: Increase numCandidates. Start at 10x limit and scale up. Validate against exact search.
Quick Reference
Complete End-to-End Example
import voyageai
from pymongo import MongoClient
# Setup
vo = voyageai.Client(api_key="YOUR_VOYAGE_API_KEY")
client = MongoClient("YOUR_MONGODB_CONNECTION_STRING")
collection = client["sample_mflix"]["movies"]
# Generate query embedding
query = "sci-fi movies set in outer space with dramatic storylines"
result = vo.embed(texts=[query], model="voyage-3.5-lite", input_type="query")
query_embedding = result.embeddings[0]
# ---- Basic Vector Search ----
pipeline = [
{
"$vectorSearch": {
"exact": False,
"index": "vectorPlotIndex",
"path": "plot_embedding",
"queryVector": query_embedding,
"numCandidates": 100,
"limit": 10
}
},
{
"$project": {
"title": 1,
"plot": 1,
"score": {"$meta": "vectorSearchScore"}
}
}
]
# Execute
x = collection.aggregate(pipeline)
for doc in x:
print(f"[{doc['score']:.3f}] {doc['title']}")
# ---- Filtered Vector Search (movies after 2010) ----
filtered_pipeline = [
{
"$vectorSearch": {
"index": "vectorPlotIndex",
"path": "plot_embedding",
"queryVector": query_embedding,
"numCandidates": 100,
"filter": {"year": {"$gt": 2010}},
"limit": 10
}
},
{
"$project": {
"title": 1,
"plot": 1,
"year": 1,
"score": {"$meta": "vectorSearchScore"}
}
}
]
y = collection.aggregate(filtered_pipeline)
for doc in y:
print(f"[{doc['year']}] [{doc['score']:.3f}] {doc['title']}")
References
| Resource | URL |
|---|---|
| MongoDB Atlas Vector Search Docs | https://www.mongodb.com/docs/atlas/atlas-vector-search/vector-search-stage/ |
$vectorSearch Query Reference |
https://www.mongodb.com/docs/vector-search/query/aggregation-stages/vector-search-stage/ |
| Vector Search Index Reference | https://www.mongodb.com/docs/vector-search/index/vector-search-type/ |
| Voyage AI voyage-3.5-lite Model | https://docs.voyageai.com/docs/embeddings |
| HNSW Algorithm (Original Paper) | https://arxiv.org/abs/1603.09320 |
| Related Tutorial in This Repo | MongoDB_IndexingAlgorithms.md (HNSW, ANN, Skip Lists) |
About the Author
KrishnaMohan Seelam — Senior Engineer
I write about developer tools, databases, and applied AI.
If you found this useful, give it a 👏 and follow me for more!
]]>